API Node Guide
Overview
The API Node allows you to interact with external APIs and web services directly from your NINA workflows. This versatile node can both fetch data from external sources and send workflow data to external systems, enabling seamless integration with a wide range of services and platforms.
Use Cases
- Fetching data from external security tools and services
- Retrieving threat intelligence from public APIs
- Sending scan results to security platforms
- Querying domain information from WHOIS or DNS services
- Interacting with custom internal APIs
- Retrieving vulnerability data from databases
- Connecting to webhooks
Creating an API Node
Basic Setup
- Drag an API Node from the node palette onto your workflow canvas
- Connect it to an input source containing data (for "out" type nodes)
- Configure the API connection details (base URL, authentication)
- Select an API endpoint to interact with
- Configure request parameters, headers, and body as needed
- Set the API node type (input or output)
API Configuration
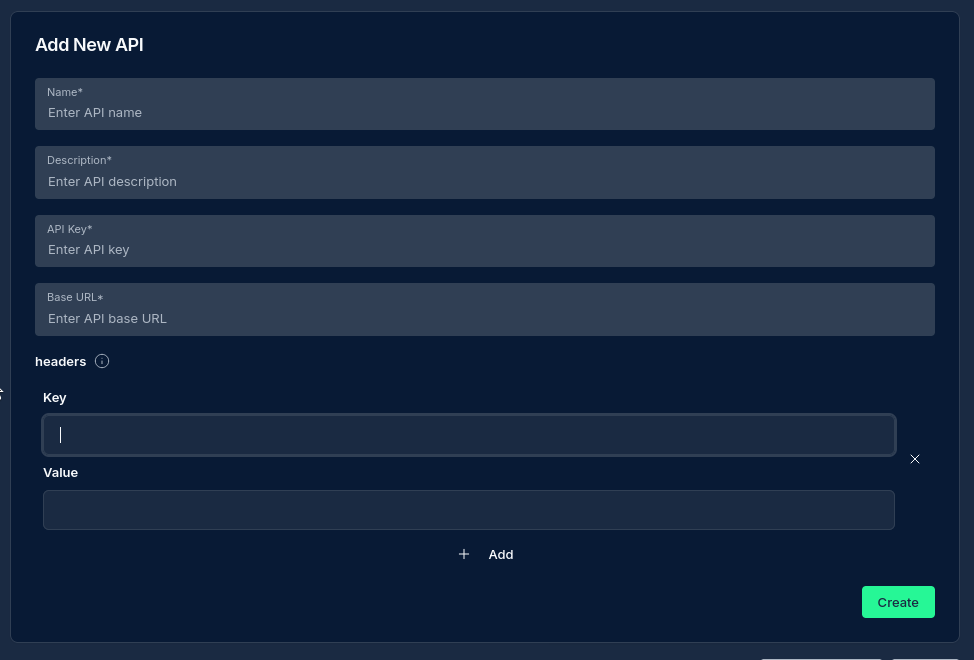
NINA separates API configuration into two components:
1. API Definition
The API definition contains the base information for connecting to an API:
- Name: A descriptive name for the API
- Description: Details about the API's purpose and functionality
- Base URL: The root URL for all API endpoints (e.g.,
https://api.example.com) - API Key: Authentication key for the API
- Headers: Additional HTTP headers required by the API
2. API Endpoints
Each API can have multiple endpoints defined:
- Name: A descriptive name for the endpoint
- Path: The endpoint path relative to the Base URL (e.g.,
/v1/users) - Method: HTTP method (GET, POST, PUT, DELETE, etc.)
- Input Schema: JSON schema defining expected input format
- Output Schema: JSON schema defining expected output format
Configuration Options
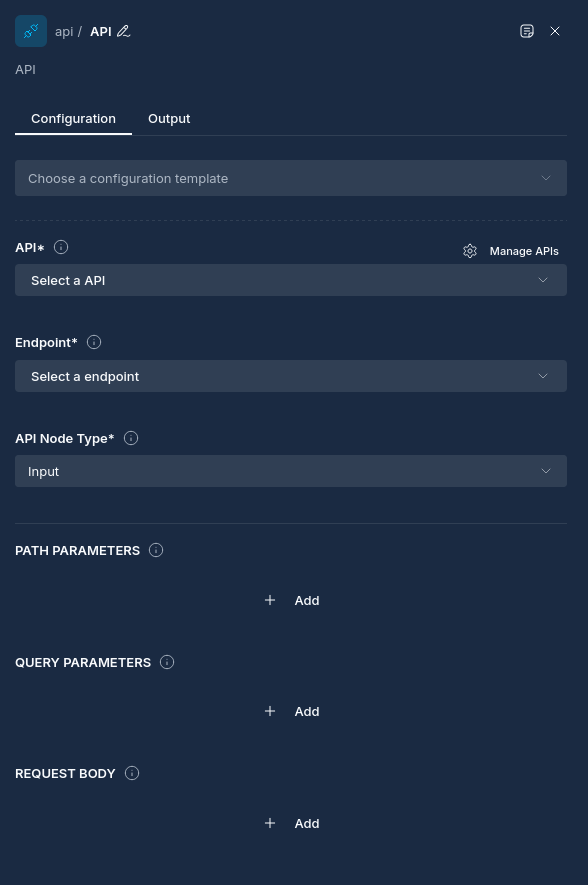
Node Properties
| Property | Description |
|---|---|
| Name | A descriptive name for the node |
| API | The API definition to use |
| Endpoint | The specific API endpoint to interact with |
| API Node Type | "in" for retrieving data, "out" for sending data |
| Path Parameters | Variables to be substituted in the endpoint path |
| Query Parameters | Parameters to be added to the request URL |
| Headers | Custom HTTP headers to include in the request (merged with API config headers) |
| Request Body | Data to be sent in the request body (for "out" type) |
| Return Contents | Include upstream node output in the request (for "out" type) |
| Include Metadata | Configuration for which workflow metadata to include in request body (for "out" type) |
API Node Types
API Nodes can be configured in two modes:
1. Input ("in") Mode
- Retrieves data from external APIs and services
- Makes GET requests to the configured endpoint
- Provides the response as output for downstream nodes
- Does not require connection to upstream nodes
2. Output ("out") Mode
- Sends data to external APIs and services
- Makes requests using the endpoint's specified method (POST, PUT, DELETE, etc.)
- Passes upstream node data in the request body
- Provides the API response as output for downstream nodes
Path and Query Parameters
Path Parameters
Path parameters are substituted directly into the endpoint path. For example, if an endpoint is defined as:
/users/{userId}/posts/{postId}
You can configure path parameters like:
{
"userId": "123",
"postId": "456"
}
This will result in a final path of /users/123/posts/456.
Query Parameters
Query parameters are added to the URL as key-value pairs after a question mark. For example, with query parameters:
{
"limit": 10,
"sort": "date",
"order": "desc"
}
The URL will include ?limit=10&sort=date&order=desc.
Custom Headers
API Nodes support custom HTTP headers that can be configured at multiple levels with a clear precedence order.
Key Concept: Headers are merged per-key, not replaced entirely. Each header key takes its value from the highest-priority source that defines it. All non-conflicting headers from all sources are included in the final request.
Header Merging and Precedence
Headers are merged across all sources, with individual header keys taking precedence based on their source. Later sources override earlier sources on a per-key basis, not as an all-or-nothing replacement.
Precedence Order (lowest to highest):
- API Config Headers - Headers defined in the API configuration (applies to all endpoints)
- Upstream Node Headers - Headers provided by upstream nodes in their output
- Node Headers - Headers configured directly on the API Node (highest priority)
How Merging Works
The merging is per-key, meaning:
- If a header key exists in multiple sources, the value from the higher-priority source wins
- Headers from lower-priority sources that don't conflict are kept
- All unique headers from all sources are included in the final request
Example:
API Config Headers:
{
"Authorization": "Bearer api-token",
"X-Service": "NINA",
"X-Environment": "production"
}
Upstream Node Output:
{
"headers": {
"X-Environment": "staging",
"X-Request-ID": "upstream-12345"
}
}
Node Headers:
{
"X-Request-ID": "node-99999",
"X-Priority": "high"
}
Resulting Merged Headers:
{
"Authorization": "Bearer api-token", // from API config (kept, no conflict)
"X-Service": "NINA", // from API config (kept, no conflict)
"X-Environment": "staging", // from upstream (overrides API config)
"X-Request-ID": "node-99999", // from node (overrides upstream & API config)
"X-Priority": "high" // from node (new, no conflict)
}
This allows you to:
- Define common headers (like authorization) at the API level that apply to all requests
- Have upstream nodes dynamically provide headers based on workflow context
- Override specific headers at the node level for special cases
- All without losing non-conflicting headers from lower priority sources
Configuring Headers
Headers can be configured as a JSON object with string key-value pairs:
{
"Content-Type": "application/json",
"X-Custom-Header": "custom-value",
"X-Request-ID": "12345"
}
Use Cases for Custom Headers
- Content Type Override: Change the content type for specific requests
- Custom Authentication: Add API-specific authentication headers
- Request Tracking: Include correlation IDs or request tracking headers
- API Versioning: Specify API version in headers
- Rate Limiting: Include rate limiting tokens or identifiers
Workflow Metadata Configuration
When using "out" type API nodes, you can optionally include workflow metadata in the request body. This is useful when external systems need to track which workflow or execution triggered the API call.
Include Metadata Options
The include_metadata configuration allows you to selectively include workflow context:
{
"include_workflow_id": true,
"include_workflow_execution_id": true,
"include_node_id": false,
"include_previous_node_id": false
}
Available Metadata Fields
- include_workflow_id: Include the workflow's unique identifier
- include_workflow_execution_id: Include the current execution's unique identifier
- include_node_id: Include this node's unique identifier
- include_previous_node_id: Include the ID of the previous node in the workflow
When enabled, these fields will be automatically added to the request body:
{
"workflow_id": "550e8400-e29b-41d4-a716-446655440000",
"workflow_execution_id": "7c9e6679-7425-40de-944b-e07fc1f90ae7",
"node_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"previous_node_id": "b2c3d4e5-f6a7-8901-bcde-f12345678901"
}
Use Cases for Metadata
- Audit Trails: Track which workflows triggered specific API actions
- Debugging: Correlate API calls with workflow executions
- Conditional Logic: External systems can apply different logic based on workflow context
- Analytics: Analyze API usage patterns by workflow
Dynamic Parameters from Upstream Nodes
API Nodes can receive parameters dynamically from upstream nodes, allowing you to build flexible workflows where the API request is configured based on data from previous steps.
Key Concept: All parameters (path_parameters, query_parameters, request_body, headers) are merged per-key across sources. Node-defined values override upstream values for individual keys, but non-conflicting keys from both sources are kept.
How It Works
When an API Node has input connections from upstream nodes, it will automatically extract and merge parameters from those nodes' outputs. The upstream node's output JSON can include special keys that the API Node recognizes:
path_parameters- Parameters to substitute in the endpoint pathquery_parameters- Parameters to add to the URL query stringrequest_body- Data to include in the request body (for "out" type nodes)headers- Custom headers to add to the request (merged with node and API config headers)
Parameter Merging Order
All parameters (path_parameters, query_parameters, request_body, and headers) are merged on a per-key basis across sources, with later sources taking precedence for individual keys:
For Headers:
- API Config Headers - Headers defined in the API configuration (lowest priority)
- Upstream Node Headers - Headers from upstream node outputs (middle priority)
- Node Headers - Headers configured on the API Node (highest priority)
For Other Parameters (path_parameters, query_parameters, request_body):
- Upstream Node Parameters - Parameters from upstream node outputs (lower priority)
- Node-Defined Parameters - Parameters configured directly on the API Node (highest priority)
Important: This is a per-key merge, not an all-or-nothing replacement. If an upstream node provides {"userId": "123"} and the node defines {"limit": 50}, the result will be {"userId": "123", "limit": 50}. If both provide the same key, the node's value wins.
This means you can:
- Set default values at the API level (headers only) or on the node
- Have upstream nodes dynamically provide parameters based on workflow context
- Override specific parameters at the node level for special cases
- Keep all non-conflicting parameters from all sources
Upstream Node Output Format
To pass parameters to an API Node, the upstream node should output JSON in this format:
{
"path_parameters": {
"userId": "12345",
"resourceId": "abc-def"
},
"query_parameters": {
"limit": 50,
"filter": "active",
"sort": "created_at"
},
"request_body": {
"action": "update",
"priority": "high"
},
"headers": {
"X-Request-Priority": "high",
"X-Custom-Tag": "automated"
}
}
All four keys are optional - include only the parameters you need to pass.
How API Nodes Work
Input ("in") Mode
When an "in" API Node is executed:
- The node constructs a request URL using the base URL and endpoint path
- Path parameters are substituted in the endpoint path
- Query parameters are added to the URL
- Headers (including authentication) are added to the request
- A GET request is made to the constructed URL
- The API response is processed and stored as the node's output
- Downstream nodes can access this data for further processing
Output ("out") Mode
When a workflow with an "out" API Node is executed:
- The node receives data from upstream nodes
- Parameters are extracted and merged from upstream nodes' outputs (path_parameters, query_parameters, request_body, headers)
- Node-defined parameters are merged with upstream parameters (node-defined values override upstream values per-key)
- The request URL is constructed using the base URL and endpoint path
- Path parameters (merged) are substituted in the endpoint path
- Query parameters (merged) are added to the URL
- Headers are constructed by merging (per-key) in order:
- API config headers (lowest priority)
- Upstream node headers (middle priority)
- Node-defined headers (highest priority)
- A request body is constructed by merging:
- If "Include Metadata" is configured, selected workflow metadata fields are added first (workflow_id, workflow_execution_id, node_id, previous_node_id)
- Merged request_body parameters from upstream nodes and node configuration
- If "Return Contents" is enabled, the upstream node's output is included as "content"
- The request is made using the endpoint's specified method (POST, PUT, etc.)
- The API response is processed and stored as the node's output
- Downstream nodes can access this response for further processing
Authentication Methods
API Nodes support different authentication methods through the API configuration:
- Bearer Token: Added as an "Authorization: Bearer [token]" header
- API Key: Stored securely in the API configuration
- Custom Headers: Any custom authentication headers required by the API
Best Practices
- API Reuse: Create reusable API configurations for frequently used services
- Request Optimization: Only include necessary data in API requests to minimize payload size
- Response Processing: Consider using Script Nodes to extract and transform API responses
- Path Parameters: Use descriptive names that match the endpoint path variables
- Header Organization: Define common headers at the API level, use node-level headers for overrides
- Metadata Selection: Only enable metadata fields that external systems actually need
- Understand Per-Key Merging: Parameters and headers are merged per-key, not replaced entirely - you can mix defaults with overrides
- Leverage Precedence: Use API config for common values, upstream nodes for dynamic values, and node config for final overrides
- Dynamic Headers: Use upstream node outputs to dynamically provide headers based on workflow context
- Avoid Conflicts: Be mindful of which keys you're overriding at each level to avoid unexpected behavior
Example Configurations
Example 1: Fetching Data from a Security API (Input Mode)
API Configuration:
- Name: "ThreatIntel API"
- Base URL:
https://api.threatintel.example.com - API Key:
[your-api-key]
Endpoint Configuration:
- Name: "Get Indicators"
- Path:
/v1/indicators - Method: GET
API Node Configuration:
- API Node Type: "in"
- Query Parameters:
{
"type": "domain",
"limit": 100
}
Example 2: Sending Scan Results to an API (Output Mode)
API Configuration:
- Name: "Security Platform API"
- Base URL:
https://api.securityplatform.example.com - API Key:
[your-api-key]
Endpoint Configuration:
- Name: "Submit Scan Results"
- Path:
/v2/results - Method: POST
API Node Configuration:
- API Node Type: "out"
- Return Contents: true
- Request Body:
{
"scan_type": "vulnerability",
"scan_date": "2024-04-24",
"environment": "production"
}
Example 3: Using Custom Headers and Workflow Metadata
API Configuration:
- Name: "Internal Tracking API"
- Base URL:
https://internal.tracking.example.com - Headers:
{
"Authorization": "Bearer your-api-token",
"X-Service": "NINA"
}
Endpoint Configuration:
- Name: "Log Workflow Event"
- Path:
/v1/events - Method: POST
API Node Configuration:
- API Node Type: "out"
- Headers (node-level overrides):
{
"X-Priority": "high",
"X-Event-Type": "scan-complete"
} - Include Metadata:
{
"include_workflow_id": true,
"include_workflow_execution_id": true,
"include_node_id": false,
"include_previous_node_id": true
} - Request Body:
{
"event": "scan_completed",
"timestamp": "2024-04-24T10:30:00Z"
}
Resulting Request:
- Headers will include:
Authorization,X-Service,X-Priority,X-Event-Type - Request body will include:
workflow_id,workflow_execution_id,previous_node_id,event,timestamp
Troubleshooting
| Issue | Resolution |
|---|---|
| Authentication failures | Verify API key is correct and not expired |
| Connection timeout | Check network connectivity and API service status |
| Invalid response format | Verify the API is returning the expected data format |
| Path parameter errors | Ensure all path parameters in the endpoint are provided |
| Rate limiting | Implement delays or reduce frequency of API calls |
| 404 Not Found | Verify the endpoint path is correct |
| 400 Bad Request | Check request body format against the API's requirements |
| Header conflicts | Check header precedence: API config < upstream < node. Verify which source is providing the conflicting key |
| Missing workflow metadata | Ensure "Include Metadata" is configured for "out" type nodes |
| Headers not applied | Verify headers are defined as JSON object with string values |
| Unexpected parameter values | Remember parameters merge per-key - check all three sources (API config, upstream, node) for the conflicting key |
| Some headers missing | Merging is per-key, not all-or-nothing - verify each source is providing expected keys |
Next Steps
After configuring your API Node, you might want to:
- Add a Script Node to process and transform the API response
- Use the API response data to trigger conditional workflow branches
- Chain multiple API calls together for complex data gathering
Updated: 2026-01-22